
LLaMA2 PyTorch from Scratch (WiP)
Article Summary (TL;DR)
This article is a summary of the paper "LLaMA2 from Scratch: An Own Implementation" and provides helpful guidance for the accompanying repository here. The paper is authored by Thomas Ziereis and Christian Bernhard, and supervised by Andrew Luckow in the context of the lecture: Advanced Analytics and Machine Learning (AAML).
{kind=link}
This article aims to help you understand the inner workings of the LLaMA2 model, from architecture to inference, focusing on optimizing the model for consumer hardware through quantization and C++/CUDA enhancements. You'll find a concise overview of the project's goals, setup, model implementation, optimization techniques, and practical tips for efficient inference. For comprehensive details, please refer to the paper and the repository.
Overview/Usage
Setup Guide
- Install Dependencies
Run the following command to install all required Python packages:
pip install -r requirements.txt
- Download Model Weights
Download the Meta LLaMA2 7B weights from here. We highly recommend downloading the llama2-7b-chat model for superior text generation performance.
- Organize Model Files
Create a /bin directory in the project root and move the llama-2-7b-chat directory and tokenizer.model file into the /bin directory.
- Export Model Weights
Export the model weights into our binary file format by running:
python3 export.py --help
Note: This process requires at least ~28GB of peak RAM.
- Compile the C/CUDA Library
Compile the library used for quantization and model inference with the following commands:
mkdir build && cd build
cmake .. -DCUDA=ON # with CUDA support
cmake .. # without CUDA
make
- Run Text Completion
You can now run text completion using the base model:
python3 run.py --bin=bin/chat-llama.bin "Richard Feynman was a "
Note: This can be slow. For better performance, quantize the model weights as described below.
Quantization for Improved Performance
Quantization reduces the precision of the model's weights, significantly enhancing performance and allowing the model to run on consumer hardware. The project supports 8-bit and 4-bit quantization. For GPUs, a 4-bit forward pass is implemented to accommodate hardware constraints, enabling the model to run on almost any GPU with around 6GB of VRAM.
LLaMA Architecture Overview
The LLaMA2 model architecture can be easily understood using the PyTorch implementation. Below is a simplified version of the PyTorch model code showcasing the core components of the model. This version is designed to be easy to read and understand, focusing on the structure and flow of the model.
import torch
import torch.nn as nn
class EncoderBlock(nn.Module):
def __init__(self, args):
super().__init__()
self.attention_norm = RMSNorm(args.dim, args.norm_eps)
self.attention = SelfAttention(args)
self.ffn_norm = RMSNorm(args.dim, args.norm_eps)
self.feed_forward = FeedForward(args)
def forward(self, x, pos):
normalized = self.attention_norm(x)
att = self.attention(normalized, pos)
encoded = x + att
ffn_normalized = self.ffn_norm(encoded)
ffn_out = self.feed_forward(ffn_normalized)
out = encoded + ffn_out
return out
class Transformer(nn.Module):
def __init__(self, args):
super().__init__()
self.params = args
self.dim = args.dim
self.vocab_size = args.vocab_size
self.tok_embeddings = nn.Embedding(args.vocab_size, args.dim)
self.layers = nn.ModuleList([EncoderBlock(args) for _ in range(args.n_layers)])
self.norm = RMSNorm(args.dim, args.norm_eps)
self.output = nn.Linear(args.dim, args.vocab_size, bias=False)
def forward(self, token, pos):
embedding = self.tok_embeddings(torch.tensor([token], dtype=torch.long))[0, :]
for layer in self.layers:
embedding = layer(embedding, pos)
embedding_normalized = self.norm(embedding)
output = self.output(embedding_normalized).float()
return output
LLaMA2 Architecture
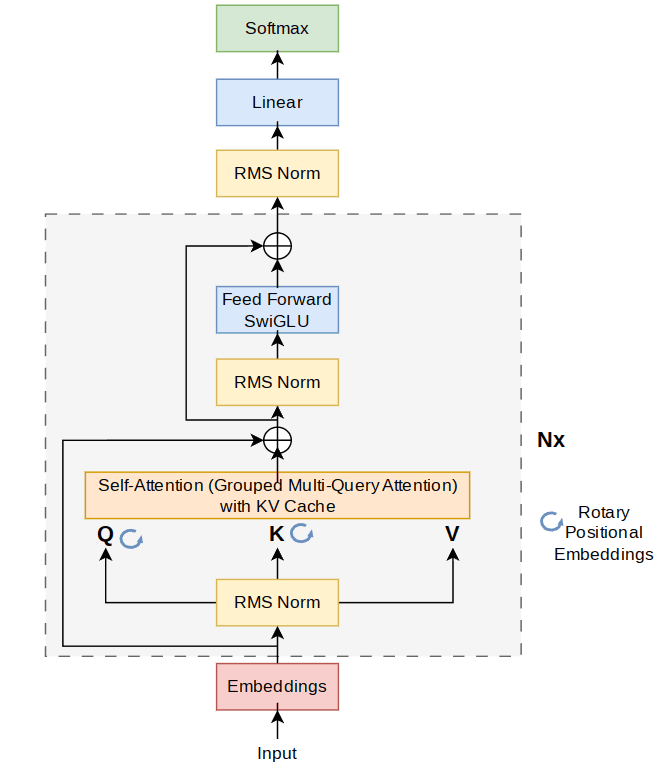
The PyTorch implementation above provides a clear view of the LLaMA2 architecture. Each EncoderBlock contains an attention mechanism and a feedforward network, both of which are normalized using RMSNorm. These blocks are stacked together in the Transformer class, which processes the input tokens through embedding, sequentially through each layer, and finally through an output linear layer to generate predictions.
This architecture is implemented in C++ in our project for performance optimization, but the PyTorch version is an excellent reference for understanding the model's structure. The corresponding C++ implementation replicates this architecture, ensuring the same logical flow and functionality but with enhanced performance suitable for consumer hardware.
Quantization and Efficient Model Execution
The heart of the LLaMA2 implementation lies in its C++ code, but to optimize for consumer hardware, we use quantization techniques. Here's an overview of how we achieved efficient model execution through quantization, based on the information from the paper and the repository.
Why Quantization?
Quantization is essential for running large models like LLaMA2 on consumer hardware because it reduces the precision of the model weights, significantly enhancing performance. Quantization techniques such as float16, int8, and int4 are used to convert the weights to lower precision formats. This helps in:
- Reducing memory footprint
- Accelerating computation
- Allowing models to run on hardware with limited resources
Custom Quantization Implementation
To have full control over the quantization process, we implemented our own quantization code. This allows for selective precision adjustments where some operations still work with high precision values to maintain accuracy. For example, small parameter matrices might not benefit from quantization, while large matrices do, ensuring a balance between performance and accuracy.
Data Format and Quantization Process
We saved the model weights in our own .bin format to better handle them since the .pth structure of PyTorch is not always controllable. This custom format allows for better management of weight loading and quantization. Quantization processes involve converting weights to lower precision and sometimes dequantizing back to higher precision for specific operations to maintain model accuracy.
By selectively quantizing and dequantizing weights, we ensure that critical computations maintain high precision while still benefiting from the reduced memory and computational requirements of quantization. This approach strikes a balance between performance and accuracy, leveraging the strengths of both high and low precision arithmetic.
For detailed explanations and the reasoning behind our approach, please refer to the paper.
Inference and Text Generation
To utilize the LLaMA2 model, you can run inference and generate text using the provided scripts. Here’s a guide on how to use the model via the command line and an explanation of the different text generation strategies.
Command Line Usage
You can generate text using the run.py script. Here’s an example command:
python3 run.py --bin=bin/llama_q8.bin --max-toks=200 --method=top_p --temperature=0.3 --top_p=0.9 --top_k=5 "Richard Feynman was a "
This command runs the run.py script with the specified parameters, generating text based on the prompt "Richard Feynman was a ".
Text Generation Process
The text generation is handled by the generate.py script, which includes the generate_text function. Below is a simplified version of the generate_text function to illustrate the process:
import torch
import os
from qllama import Runtime
from llama_utils import load_tokenizer
import time
tokenizer = load_tokenizer("bin/tokenizer.model")
def generate_text(llama: Runtime, prompt: str, max_toks: int = 30, method: str = 'greedy', temperature: float = 0.1,
top_p: float = 0.1, top_k: int = 10) -> str:
input_tokens = tokenizer.encode(prompt)
output_tokens = []
start_time = time.time()
# Fill KV Cache with input tokens
first_token = input_tokens[0]
_ = llama.forward(first_token, len(output_tokens))
output_tokens.append(first_token)
for token in input_tokens[1:]:
_ = llama.forward(token, len(output_tokens))
output_tokens.append(token)
# Generate completion tokens
while len(output_tokens) < max_toks:
latest_token = output_tokens[-1]
out = llama.forward(latest_token, len(output_tokens))
out = torch.tensor(out)
if method == 'greedy':
next_token = torch.argmax(out).item()
elif method == 'top_p':
next_token = sample_top_p(torch.softmax(out / temperature, dim=-1), top_p)
elif method == 'top_k':
next_token = sample_top_k(torch.softmax(out / temperature, dim=-1), top_k)
if next_token == tokenizer.eos_id():
break
output_tokens.append(next_token)
total_time = time.time() - start_time
tokens_per_second = len(output_tokens) / total_time
print(f"Tokens per second: {tokens_per_second:.2f}")
return tokenizer.decode(output_tokens)
def sample_top_p(probs: torch.Tensor, p: float) -> int:
# ...
Inference Strategies
-
Greedy: Always selects the token with the highest probability. This method can result in repetitive and less creative outputs.
-
Top-P (Nucleus Sampling): Selects tokens from the smallest set whose cumulative probability is at least
p. This method allows for more diverse and creative outputs compared to greedy sampling. -
Top-K: Selects the next token from the top
ktokens with the highest probabilities. This method also promotes diversity and creativity in the generated text.
Temperature: Adjusts the randomness of the token selection. Lower temperatures make the model more deterministic (less random), while higher temperatures increase randomness.
Running the Inference
To generate text using the model, run the run.py script with the appropriate arguments. For example:
python3 run.py --bin=bin/llama_q8.bin --max-toks=200 --method=top_p --temperature=0.3 --top_p=0.9 --top_k=5 "Richard Feynman was a "
This command will generate text based on the provided prompt using the specified parameters for sampling method and temperature.
For detailed benchmark values and performance metrics, refer to the paper.
CUDA Implementation
To further accelerate the LLaMA2 model, we implemented the core functionalities using CUDA to leverage GPU compute power. This allows for significantly faster inference times compared to CPU-only implementations.
Benefits of CUDA
- Parallel Processing: GPUs can handle thousands of threads simultaneously, making them ideal for the parallel nature of neural network computations.
- Speed: CUDA implementations can drastically reduce the time required for inference by offloading heavy computations to the GPU.
- Efficiency: Utilizing GPU resources can improve the overall efficiency of the model, making it feasible to run on consumer-grade hardware.
How to Use the CUDA Implementation
To use the CUDA-accelerated version of the model, follow the setup guide provided in the README:
- Install Dependencies
Ensure you have CUDA installed on your system. You can verify this by running:
nvcc --version
Then, install the required Python packages:
pip install -r requirements.txt
- Compile the CUDA Library
Compile the library used for quantization and model inference with CUDA support:
mkdir build && cd build
cmake .. -DCUDA=ON
make
- Running Inference with GPU
When running the run.py script, add the --gpu flag to enable GPU support:
python3 run.py --bin=bin/llama_q8.bin --max-toks=200 --method=top_p --temperature=0.3 --top_p=0.9 --top_k=5 --gpu "Richard Feynman was a "
This command will utilize the GPU for inference, leveraging the CUDA implementation to accelerate the process.
For more detailed instructions and performance benchmarks, refer to the paper.
By following these steps, you can take full advantage of GPU acceleration to achieve faster and more efficient text generation with the LLaMA2 model.